University @Avira: Predicting error-related user behavior in Avira Antivirus
by Manuel J. A. Eugster and Michaela Beckenbach
The best way to learn Data Science is to do data science. Following this motto, Avira collaborated with the University of Liechtenstein and participated at the winter semester 2016/2017 seminar “Data Science” with a real-world data science problem. Liene Blija, Christian Holder, Jan Plojhar, and Martin Lukšík—four brave students—accepted the challenge to tackle one of our prediction problems we face at Customer Insights Research1 at Avira.
Challenge
The challenge at hand was to predict error-related user behavior in Avira Antivirus. In more detail, the students got a sample data set of device specific error, installation, and uninstallation events.
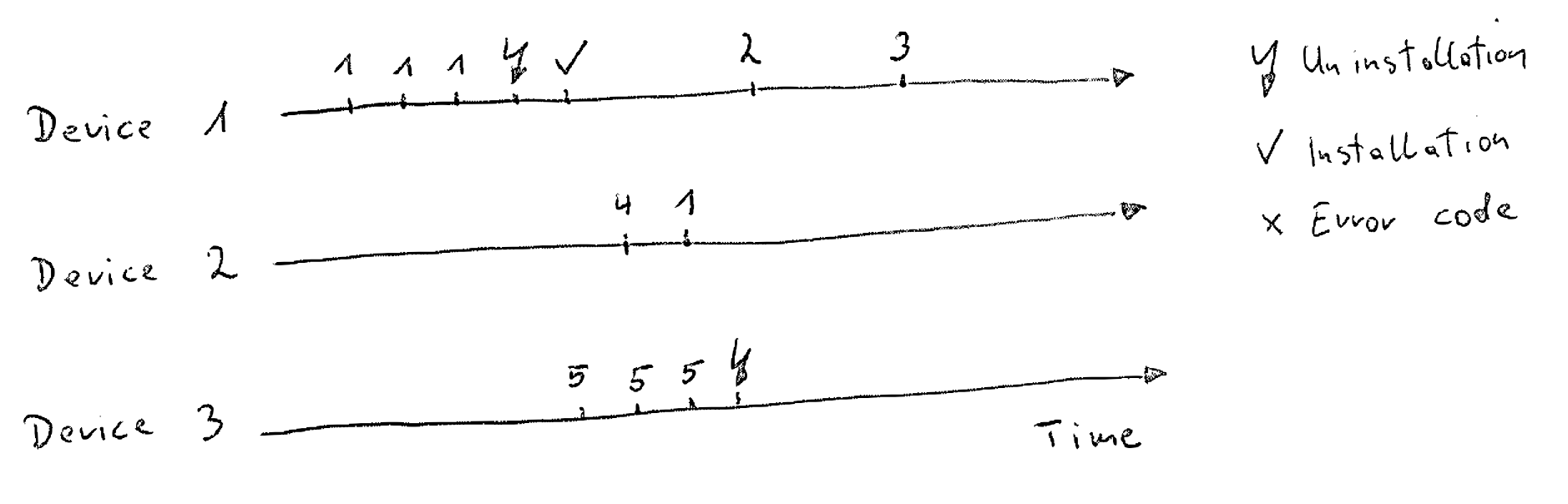
The goal was to find patterns of error codes that lead to an uninstallation. The
figure above illustrates the idea: A series of error events with error code 5
lead to an uninstallation of the product and the
churn of the user. On the other hand, error events with the code 1 lead to a
re-installation (if there is no leading error code 4), whereas error
codes 2 and 3 do not lead to any user action. This is of course a very
simplified illustration and—as the students were about to find out—data
science reality is a bit more complex…
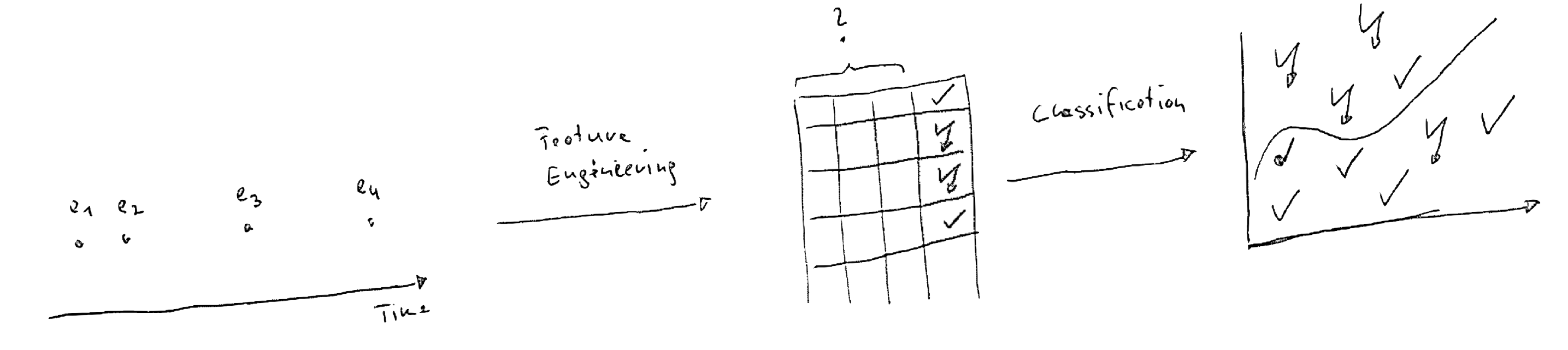
The project covered the full Data Science Lifecycle. Some of the challenges the student faced, were: First, event data is not ready for classical predictive modeling and (clever) feature engineering plays a significant role. Second, the data is highly imbalanced, meaning that only a small number of cases really lead to an uninstallation. Third, their solutions should be fully reproducible and, for example, easily applicable to a new sample data set spanning a different time frame.
Students from @uni_li here at @Avira talking and discussing about their data science project. Awesome! pic.twitter.com/f0euEoGdNo
— Manuel J. A. Eugster (@mjaeugster) November 15, 2016
Results
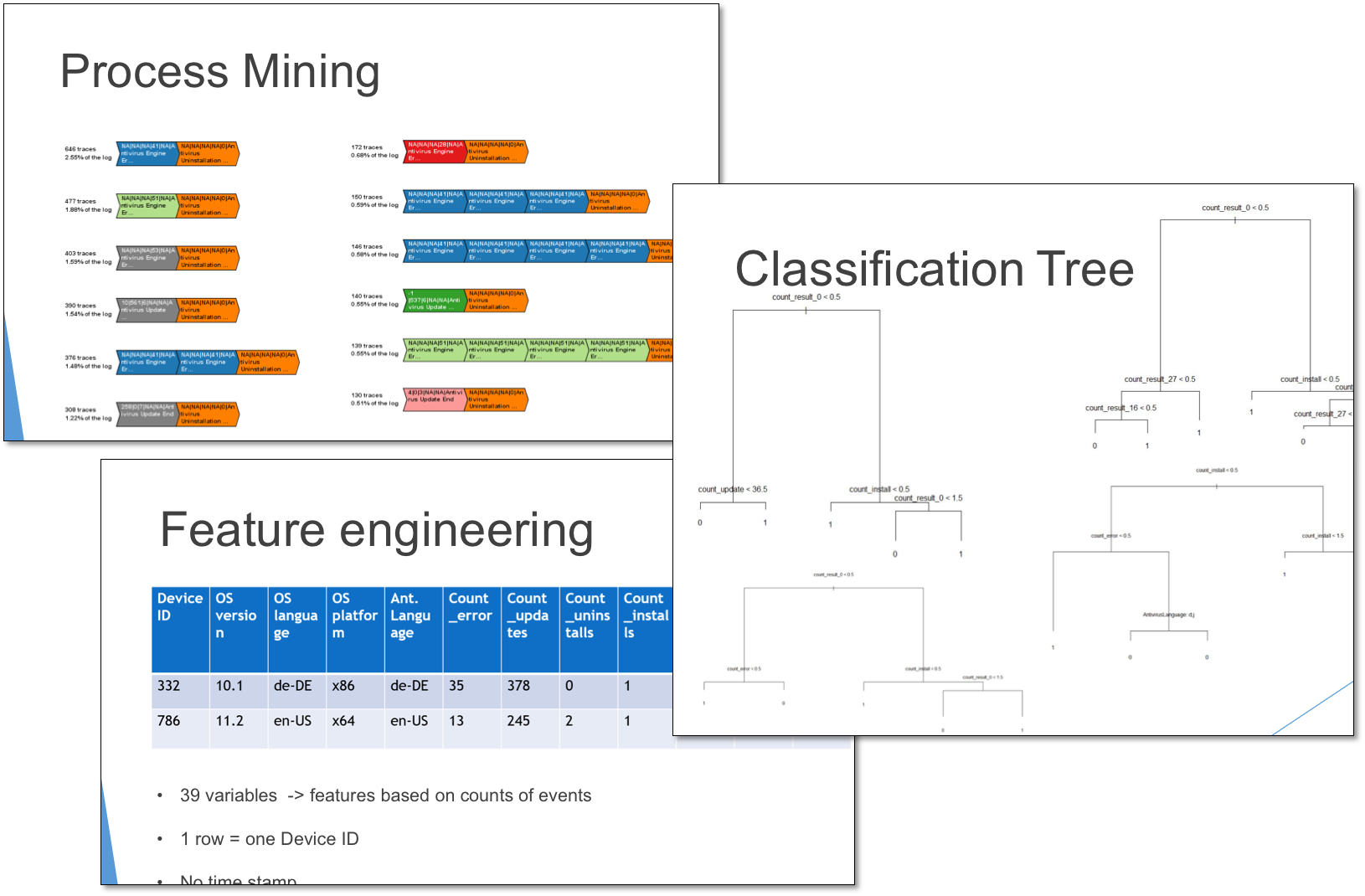
The team used various methods to analyse the data from different angles. For a first exploratory analysis they used common statistical visualizations like time series plots and the more sophisticated technique of process mining. Process mining gave them a first idea if there are any combinations of events building some common patterns (not necessarily leading to an uninstallation). Based on this information and together with some domain knowledge, potentially useful features were engineered. To build a predictive model the team then benchmarked various linear and non-linear algorithms (logistic regression, support vector machines, classification trees, and random forests) on a training set to find the best one. Their analyses showed that the random forest algorithm was the best performing algorithm with an accuracy of about on a balanced data set.
Presentation
The students presented their final results at the second 4ländereck Data Science Meetup hosted by the University of Liechtenstein. The students’ work was a first proof-of-concept that showed us that it is possible to detect patterns of error codes with a relationship to uninstallation. This is very valuable information to us—supporting our idea of improving our products with, for example, a proactive support system.
We congratulate the students for mastering this data science project successfully!
#4leds meetup with #DataScience students @uni_li presenting results based on #Avira data. Great job done! Congrats to the team! pic.twitter.com/ddKZGNK7bz
— Michaela Beckenbach (@MichiBeckenbach) January 26, 2017
-
The students were supervised by Manuel Eugster and Michaela Beckenbach. ↩
Subscribe via RSS
{kind=link}