One option model¶
[1]:
from prayas import *
The experiment consists of multiple variants and in each variant the visitor has only one option to choose. A detailed explanation of the methodology is available in Bayesian A/B Testing for Business Decisions by Shafi Kamalbasha and Manuel J. A. Eugster (2020).
Setup the model and define the four variants:
[2]:
m = OneOptionModel(["Discount 20", "Discount 10",
"Discount 40", "Discount 50"],
baseline = "Discount 20")
The full model specification is:
[3]:
print(m)
One option model
Variants : Discount 20, Discount 10, Discount 40, Discount 50
Baseline : Discount 20
Measures : conversion
Primary measure : conversion
Maximum loss threshold: 5
Set the result of the experiment:
[4]:
m.set_result(successes=[139, 147, 149, 134],
trials=[15144, 15176, 14553, 14948])
Investigate the result:
[5]:
m.plot();
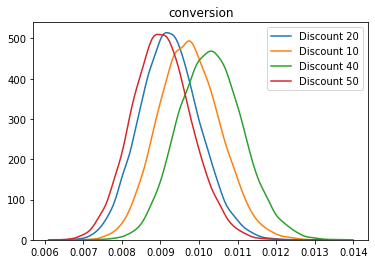
The plot shows the posteriors for the conversion rate based on the underlying one option model. The decision for this experiment is:
[6]:
m.decision()
[6]:
| Variant | Measure | ProbabilityToBeBest | ProbabilityToBeatBaseline | UpliftFromBaseline | PotentialLossFromBaseline | MaxUplift | MaxPotentialLoss | |
|---|---|---|---|---|---|---|---|---|
| 0 | Discount 40 | conversion | 0.5833 | 0.8277 | 11.380219 | 1.178262 | 14.194803 | 2.375415 |
In this experiment, the variant ‘Discount 40’ has the hightest probability to be the best with 58%. It is 82% better than the baseline with an uplift of 11%. If we go with ‘Discount 40’, there is still a change that is not better the baseline and the potential loss is about 1%.
The decision is based on the defined primary measure and maximum acceptable loss. The default values are conversion as the primary measure and 5% as the maximum acceptable loss. To change the default values, change the parameters of the model in the setup step:
m.primary_measure = "..."m.loss_threshold = "..."
These two parameters are not part of the decision function but part of the model. This should highlight the fact that the parameters should be defined during the experiment design and setup stage and are not parameters to play around in the analysis stage.
Get more details into the experiment and the decision:
[7]:
m.score_baseline()
[7]:
| Variant | Measure | ProbabilityToBeBest | ProbabilityToBeatBaseline | UpliftFromBaseline | PotentialLossFromBaseline | MaxUplift | MaxPotentialLoss | |
|---|---|---|---|---|---|---|---|---|
| 0 | Discount 40 | conversion | 0.58700 | 0.82475 | 11.605663 | 1.160935 | 14.214564 | 2.482101 |
| 1 | Discount 10 | conversion | 0.25255 | 0.67210 | 5.451555 | 2.617965 | 8.013833 | 7.605213 |
| 2 | Discount 20 | conversion | 0.09685 | 0.00000 | 0.000000 | 0.000000 | 2.428856 | 11.302390 |
| 3 | Discount 50 | conversion | 0.06360 | 0.41985 | -2.313666 | 6.024267 | -2.371262 | 13.028885 |
The data frame consists of a row for each variant and measure combination. It provides:
The probability to be the best variant and the probability to beat the baseline
The estimated uplift and potential loss in percentage from the baseline if this variant is put into production
The estimated uplift and potential loss in percentage from the best variant if this variant is put into production
The package also provides a function to compute a pairwise scoring between all pairs of variants (and measures):
[8]:
m.score_pairwise()
[8]:
| Left | Right | Measure | LeftMeasure | RightMeasure | Uplift | ProbabilityUplift | ProbabilityLoss | Loss | LeftMeasureMaxLoss | Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Discount 40 | Discount 50 | conversion | 0.010238 | 0.008964 | 14.139242 | 0.86840 | 0.13160 | 0.866717 | 0.010150 | 1227.851782 |
| 1 | Discount 40 | Discount 20 | conversion | 0.010238 | 0.009179 | 11.427508 | 0.82395 | 0.17605 | 1.189304 | 0.010117 | 941.569550 |
| 2 | Discount 10 | Discount 50 | conversion | 0.009686 | 0.008964 | 8.054927 | 0.74810 | 0.25190 | 1.915019 | 0.009501 | 602.589061 |
| 3 | Discount 40 | Discount 10 | conversion | 0.010238 | 0.009686 | 5.630762 | 0.67905 | 0.32095 | 2.456991 | 0.009987 | 382.356875 |
| 4 | Discount 10 | Discount 20 | conversion | 0.009686 | 0.009179 | 5.487745 | 0.67950 | 0.32050 | 2.564085 | 0.009438 | 372.892259 |
| 5 | Discount 20 | Discount 50 | conversion | 0.009179 | 0.008964 | 2.433630 | 0.58195 | 0.41805 | 3.752384 | 0.008834 | 141.625121 |
The data frame returns a row for each pair of variants and measure combination. It provides the information on:
On average we can expect
LeftMeasureandRightMeasureper trial (depending on the measure this is average conversion, average revenue, average gain, etc.)The probability
ProbabilityUpliftthat the left variant is better than the right variant with an uplift ofUplift%The risk of going with the left variant is a maximum drop of
Loss% with a probability ofProbabilityLoss, resulting in an average ofLeftMeasureMaxLossper trial.A score based on
Uplift * ProbabilityUplift
For example, the first row tells us that for ‘Discount 40’ we can expect a 1% and for ‘Discount 50’ a 0.9% conversion rate per visitor. There is 87% probability that ‘Discount 40’ is 14.2% better than ‘Discount 50’. The risk of going with ‘Discount 40’ is a maximum drop of 83.4% with a probability of 12.9%, resulting in an averge loss of 0.01 conversions per trial.